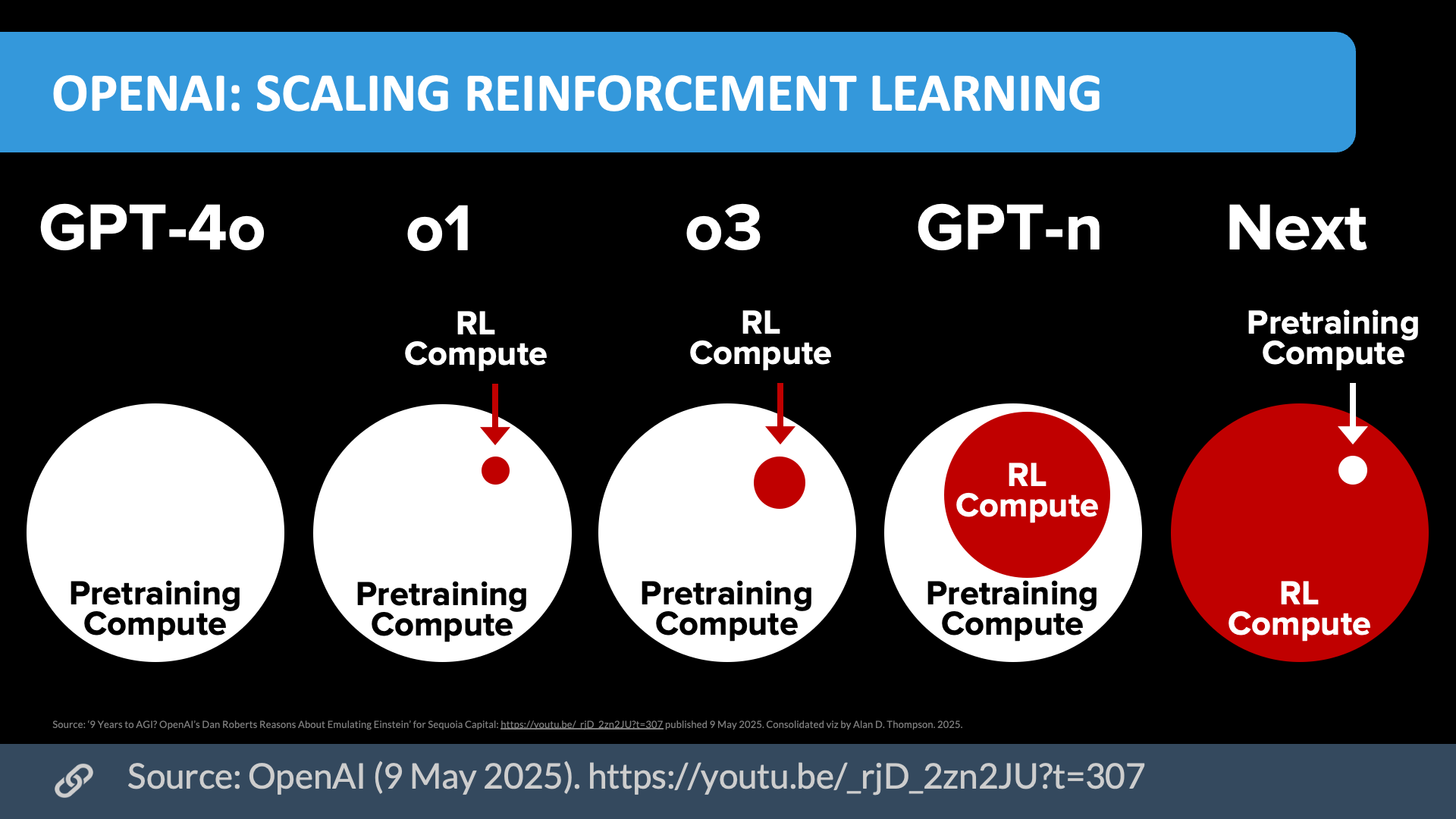
RL wasn't a waste—it needed the foundation model "cake" first (2024-2025)
Why RL Works Now (vs. 2019 criticism):
- Foundation models provide common sense: LLMs solve the "cold start" problem
- Verifiable environments: Code execution, math proofs enable RLVR
Modern Success Stories:
- OpenAI o1: Extended thinking time via RL, 83% → 94% on AIME with more compute
- DeepSeek R1: Open-source reasoning model matching o1 performance
- Code generation: RL improves debugging, test-driven refinement